Integrate Workbench and Jupyter with PySpark
This documentation describes the steps to use Posit Workbench to connect to a Spark cluster using Jupyter Notebooks and PySpark.
Requirements
- Workbench configured with Jupyter Notebooks on a Single Server
- Hadoop cluster configured with Spark and YARN
- Access from Workbench to the Spark cluster
The Workbench server must have access to the Spark cluster and the underlying configuration files for YARN and the Hadoop Distributed File System (HDFS). This typically requires you to install Workbench on an edge node (i.e., gateway node) of the Spark cluster using a Hadoop administration tool such as Cloudera Manager or Apache Ambari. You can also achieve this by copying configuration files from the Spark cluster to the Workbench server.
Posit does not support or maintain Cloudera Manager. Therefore, the examples (including UI menus and configuration options) may differ the Cloudera Manager dashboard. Please defer to Cloudera’s documentation for additional help.
In this example, Apache Hadoop YARN is used as a resource manager on the Spark cluster, and you’ll create interactive Python sessions that use PySpark.
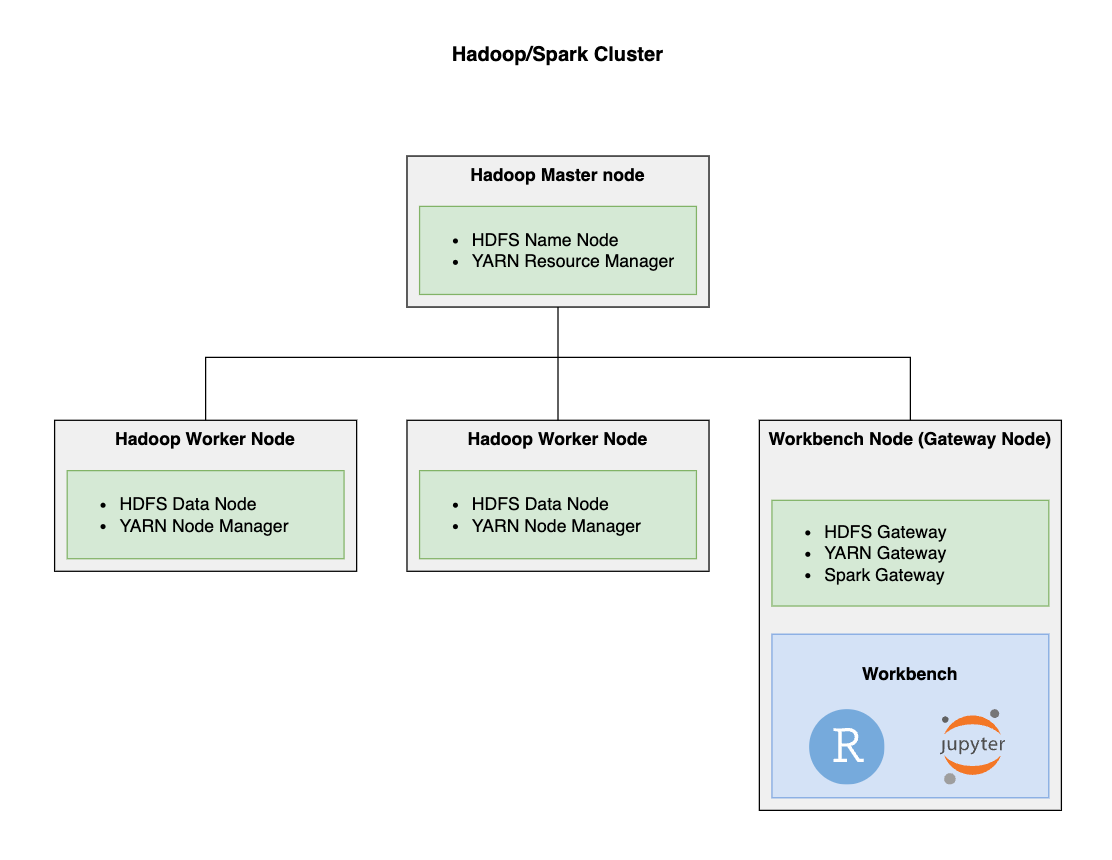
Add Workbench as an edge/gateway node
This section describes the process to add a single node as a Spark client to a Hadoop cluster. This step is typically performed by a Hadoop administrator. In this example, we use Cloudera Manager, but these steps can also be adapted to other Spark clusters such as Amazon EMR.
This section describes the process to add a single node as a Spark client to a Hadoop cluster. This is typically performed by a Hadoop administrator. This example uses Cloudera Manager, but these steps can also be adapted to other Spark clusters such as Amazon EMR.
This process may vary depending on different versions of Cloudera Distribution Hadoop (CDH), authentication, and other variables. Refer to the Cloudera Manager documentation for more information.
Add a new host to the Hadoop cluster
Since you already have a server with Workbench installed:
- Navigate to the Cloudera Manager dashboard and add a host. Please see the Cloudera Manager Adding a Host to a Cluster documentation for detailed steps.
Specify the hostname for the Workbench node
- Continue with the installation until it asks you to specify the hostname of the node to add. Add the hostname and SSH port of the Workbench node. For example:
ip-172-31-8-177.ec2.internalandSSH port: 22.- This hostname should be accessible from the Cloudera CDH cluster, Cloudera Manager will verify this when you execute a search.
- When everything is verified, continue with the installation until it asks for the login credentials for the Workbench node.
Specify the credentials for the Workbench node
For this example, we are using an Amazon EC2 instance with the username centos and authentication via a private key. You might be using a different authentication/credential mechanism depending on how you access the Workbench node.
Use the following table to define the configuration options:
| Configuration | Value |
|---|---|
| Login To All Hosts As | Another user - centos |
| Authentication Method | All hosts accept same private key |
| Private Key File | Choose the file with your private key |
You can leave the rest of the fields with their default values and continue with the installation.
The Cloudera Manager agent and parcels installation
- If the hostname and credentials are correct, Cloudera Manager installs the Cloudera Manager Agent on the Workbench node.
- The Cloudera CDH parcels then install on the node (this could take several minutes).
Verify that the new host with Workbench has been added
- Cloudera Manager inspects the hosts. If everything installed correctly, then the Workbench node will join the Hadoop cluster.
- Verify that the Workbench node appears in the list of hosts. Initially, this node will not have any roles, but you will add the necessary roles in the following step.
Add roles to the Workbench node
You can now add roles to the Workbench node. The roles that you need to add are listed as follows:
- HDFS Gateway
- YARN Gateway
- Hive Gateway
- Spark Gateway
- Spark2 Gateway (if your Cloudera CDH cluster has Spark2 installed)
The following steps show an example of how to add the Spark Gateway role to the Workbench node in Cloudera Manager. You can then repeat this process for all of the necessary roles.
For additional information including step-by-step procedures, please see Cloudera Manager Adding a Role Instance documentation.
- Navigate to the Cloudera Manager Home page, select the Instances tab and then click Add Role Instances.
- Under the Gateway option, click Select hosts.
Per Cloudera, the wizard evaluates the hardware configurations of the hosts to determine the best host for each role.
- Select the Workbench node from the list of nodes. You should now see the Workbench node selected under the Gateway option.
- Verify the hostname of the Workbench node.
- Follow the steps in the wizard and then re-deploy the client configuration.
- Repeat this process to add all of the necessary roles that are listed above.
After you’ve added all of the necessary roles, the cluster roles for the Workbench node should look similar to the following figure.
Verify that users exist on the Hadoop cluster and HDFS
It’s important that the same users that log into Workbench also exist within the Hadoop cluster because the RStudio/Jupyter sessions will run as that user. Additionally, any Spark contexts will inherit the YARN and HDFS permissions of that user.
Synchronizing users across your Workbench instance and your Hadoop cluster can be accomplished using multiple approaches. For example, both systems might be configured to the same identity provider via LDAP/AD. For more information, you can discuss this more with your Hadoop administrator.
To manually create a user in HDFS, you can run the following command (replace
<rstudio>with the actual username):$ hdfs dfs -mkdir /user/<rstudio> $ hdfs dfs -chown rstudio:rstudio /user/<rstudio>/
Verify network connectivity between Workbench and the Hadoop cluster
- Ensure that the Workbench node has network access to the Cloudera CDH cluster.
- In Amazon AWS, we recommend allowing all communication between the Cloudera CDH security group and the Workbench security group.
Using Workbench with Jupyter and PySpark
Now that Workbench is a member of the Hadoop/Spark cluster, you can install and configure PySpark to work on Workbench Jupyter sessions.
This section describes the process for a user to work with Workbench and Jupyter Notebooks to connect to the Spark cluster via PySpark.
Install PySpark in the Python environment
Install PySpark in the environments that are configured as Python kernels, for example:
sudo /opt/python/3.11.5/bin/pip3 install pyspark
PySpark cannot run with different minor versions of Python installed, be sure to use the same version of Python in Workbench and the Spark cluster.
Configure environment variables for Spark
To configure the Spark environment variables for all Jupyter sessions, create a file under
/etc/profile.d/that exports the required configuration variables, for example:File: /etc/profile.d/spark.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-1.el7_7.x86_64/jre export HADOOP_CONF_DIR=/etc/hadoop/conf
Ensure that you export a JAVA_HOME variable that matches the Java version that PySpark was compiled with. In this example, we are using Java Version 8.
Create a Spark session via PySpark
Now you are ready to create a Spark session and connect to Spark:
From the Workbench home page, create a new Jupyter Notebook or JupyterLab session.
Then, import
pysparkand create a new Spark session that uses YARN by running the following Python code in the notebook:from pyspark import SparkConf from pyspark import SparkContext conf = SparkConf() conf.setMaster('yarn-client') conf.setAppName('rstudio-pyspark') sc = SparkContext(conf=conf)
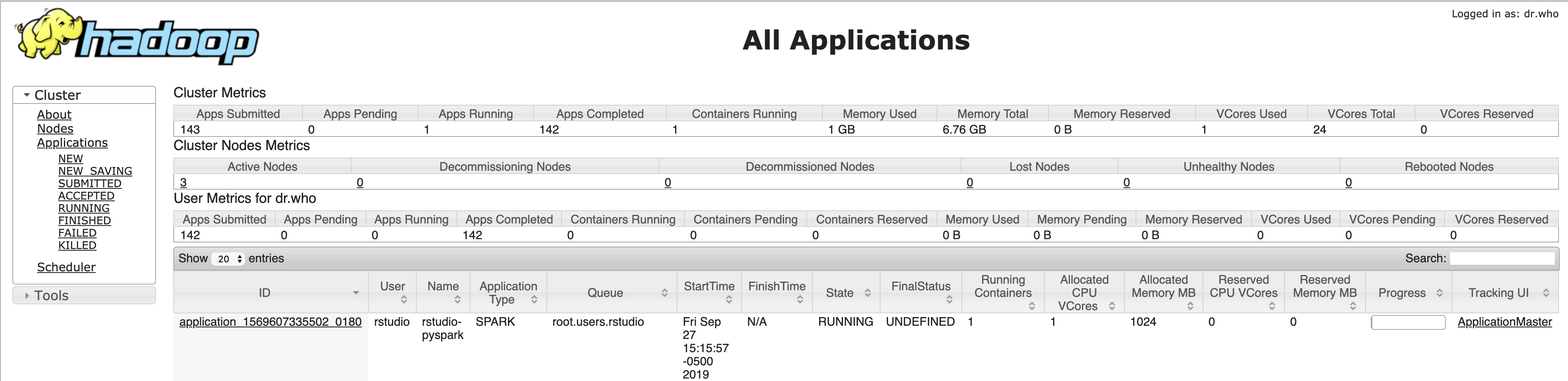
Verify that the Spark application is running in YARN
At this point, you should be able to see that the Spark application is running in the YARN resource manager.
Run a sample computation
Run the following sample code in the notebook to verify that the Spark connectivity is working as expected:
data = [1, 2, 3, 4, 5] distData = sc.parallelize(data) distData.mean()
Verify read/write operations to HDFS
Run the following sample code in the notebook to verify that writes to HDFS are working as expected:
# Save a file to HDFS rdd = sc.parallelize(range(1, 4)).map(lambda x: (x, "a" * x)) rdd.saveAsSequenceFile("saved_file")Run the following sample code in the notebook to verify that reads from HDFS are working as expected:
# Read the same file from HDFS sorted(sc.sequenceFile("saved_file").collect())