AWS ParallelCluster
You can configure Posit Workbench to use AWS’s ParallelCluster service. In this architecture, users can leverage the power and scalability of a high-performance computing (HPC) framework like Slurm in the cloud.
A ParallelCluster-based architecture can support dozens to thousands of users, and is suitable for teams that want to autoscale their computational load based on demand. However, the complexity of this architecture is unnecessary for relatively small teams with stable workloads.
Architectural overview
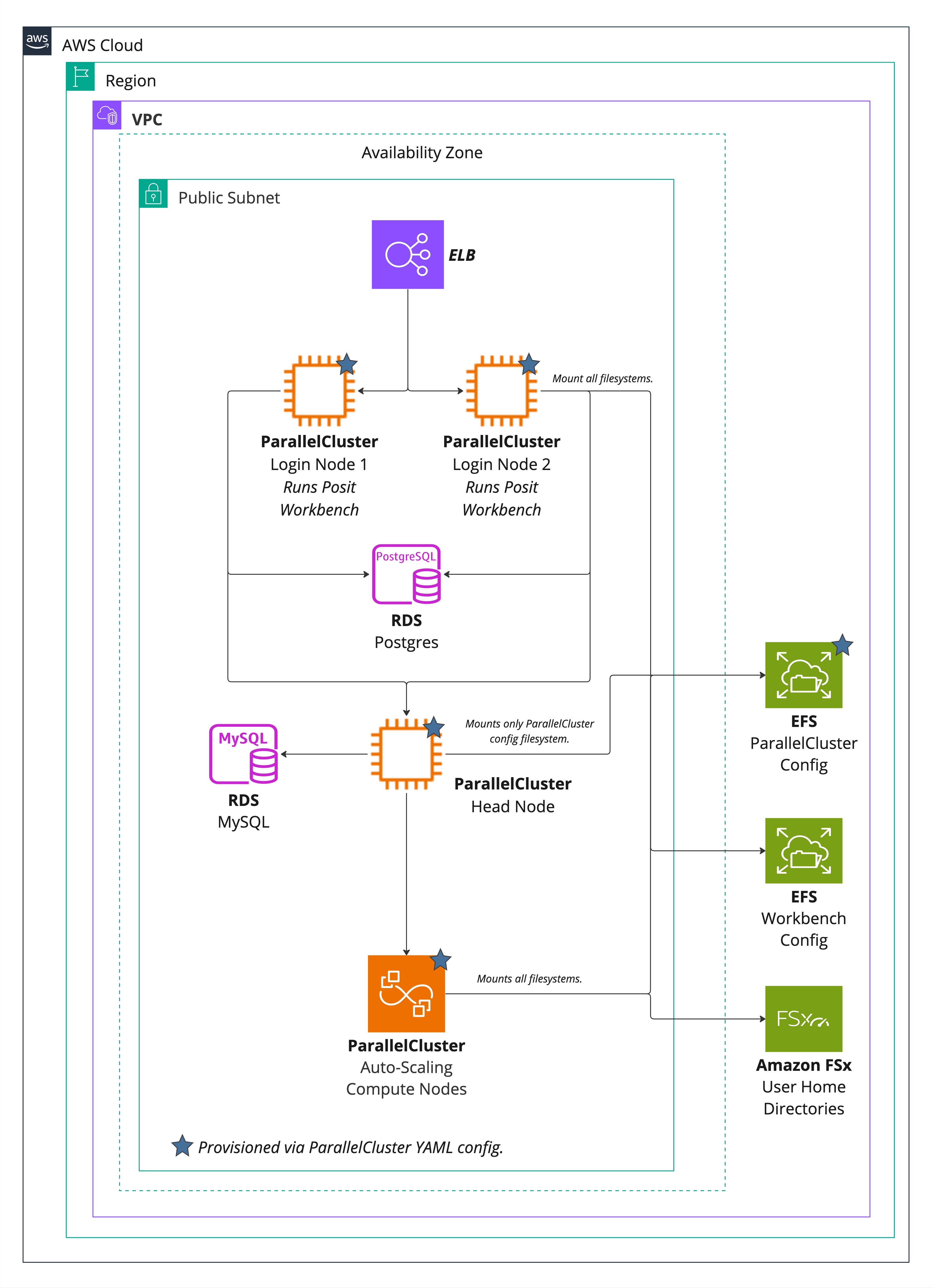
This architecture uses a combination of several services to run Posit Workbench in AWS ParallelCluster.
AWS’s ParallelCluster includes the following as sub-components:
- EC2 instances for the Slurm login, head, and compute nodes.
- An AWS Elastic Load Balancer (ELB) for ingress.
- An AWS Elastic File System (EFS) for shared data for the Slurm cluster.
- A MySQL database for Slurm Job Accounting.
For more information on typical AWS ParallelCluster configurations, see the AWS ParallelCluster documentation.
This architecture also requires the following to run Posit Workbench:
- An additional AWS EFS for Workbench configuration.
- An FSx for Lustre file system to store user home directories.
- An RDS PostgreSQL database for Posit Workbench metadata.
The minimum version of AWS ParallelCluster required for this architecture is 3.8.0.
Architecture diagram
Sizing and performance
Nodes
There are three types of nodes in a Slurm cluster:
- Compute nodes, where the R and Python code users run in Workbench execute as jobs and sessions.
- Login nodes, where users log in. Posit Workbench is hosted on the login nodes and creates jobs and sessions.
- Head nodes, which control the assignment of jobs and sessions to compute nodes.
Each of these components has different sizing requirements based on the work they perform.
Compute nodes
For deployment in AWS ParallelCluster, the appropriate size of the compute nodes depends on the workloads users run in the environment. We recommend that system administrators discuss workload needs with the end users to understand their needs and size the nodes accordingly. The Configuration and sizing recommendations article offers information on general sizing recommendations for your reference.
Login and head nodes
The sizing of login and head nodes depends on the number of concurrent sessions you expect to launch, so it is possible to estimate the number of login and head nodes purely based on the number of users of the system.
Each Posit Workbench user may start multiple concurrent sessions, though opening more than a few at a time would be rare. As a starting point, you can estimate that the session volume will equal twice the number of concurrent users at peak login times.
We have tested this architecture with one head node and the following ratio between concurrent sessions and login nodes:
| Concurrent Sessions | Login Nodes |
|---|---|
| 500 | 2 |
| 1000 | 4 |
| 2000 | 6 |
| 5000 | 6 |
Our testing used t2.xlarge nodes for both login and head nodes. It is likely that Posit Workbench functions well with fewer login nodes than indicated in the table, but that testing is still in progress. We will update this table to keep it current with our findings over time.
PostgreSQL & MySQL database
This configuration puts minimal stress on the databases. We have tested up to 5,000 concurrent sessions with db.t3.micro instances for both the Postgres and MySQL databases, and witnessed no performance degradation.
Storage
In this configuration, the EFS file systems store modest amounts of metadata, perhaps a few GBs for a production system. Since EFS autoscales with usage, the initial sizing is not important.
The appropriate size for the FSx for Lustre volume depends on end-user usage patterns. Some data science teams store very little in their home directories and will only need a few GBs per person. Other teams may download large files into their home directories and will need much more. System administrators should consult with their user groups to determine the best size for their usage patterns.
Resiliency and availability
This architecture includes Workbench on dual login nodes configured in a load-balanced setup, making it resilient to failures of either login node. AWS ParallelCluster automatically provisions new login nodes to keep the number of login nodes constant. RDS, EFS, and FSx allow for backup and redundancy configuration within the service.
This configuration sits entirely within one AWS Availability Zone (AZ), meaning that an AZ-wide outage will result in an outage of the service.
The Slurm head node is not load-balanced. If that node goes down, the system will be temporarily unavailable until a new head node is provisioned. However, sessions on compute nodes will continue running, and no data within the system will be lost.
Configuration details
Networking
AWS ParallelCluster (including all Workbench components) should be deployed inside a single public subnet with ingress using an ELB.
AWS ParallelCluster
The main configuration file of AWS ParallelCluster is a YAML file that contains all relevant information needed to deploy the HPC infrastructure.
The following must be included in the YAML file:
- AMI information - we recommend the creation of a custom AMI (see below for details).
- User authentication information (
DirectoryServicesection). - SLURM partition configuration (
Schedulingsection). - Storage configuration (
SharedStoragesection). - Login Nodes configuration (
LoginNodessection). - MySQL RDS instance information for SLURM accounting.
For more information about the AWS ParallelCluster configuration file, see the AWS Cluster configuration file documentation.
AMI
The AMI must include:
- A currently supported version of Workbench.
- All necessary versions of R and Python.
- A
systemctloverride forrstudio-server.serviceandrstudio-launcher.servicethat setsRSTUDIO_CONFIG_DIRto/opt/rstudio. See the Server Management - Alternate configuration file location section for more information. - A Workbench configuration that includes:
- Load Balancing: Enabled
- The Slurm plugin: Enabled
- The Local Plugin: Disabled
Additionally, you need to provision a MySQL database as storage for Slurm Accounting, and add the database URI and credentials to the AWS ParallelCluster YAML file, as discussed in the RDS section below.
RDS
Two RDS instances must be provisioned for this configuration:
- Configure the first RDS instance with an empty PostgreSQL database for the Posit Workbench metadata. Ensure that this RDS instance is reachable over the network by all Workbench hosts (the login nodes).
- Configure the second RDS instance with an empty MySQL database for Slurm Accounting metadata. This RDS instance needs to be reachable only by the ParallelCluster head node. Configure this RDS in the
Schedulingsection of the ParallelCluster YAML config.
User authentication
AWS ParallelCluster allows the configuration of user authentication in the DirectoryService section of the YAML config file. The most simple configuration for Workbench is to leverage this setup via PAM authentication. It also is possible to use SSO services such as SAML and OpenID Connect in Workbench that then will use PAM sessions only.
EFS
By default, AWS ParallelCluster exports the following file directories from the Slurm head node, and mounts them on all other nodes:
/opt/slurm/opt/parallelcluster/shared/opt/intel/opt/parallelcluster/shared_login(only mounted on the login nodes)
We recommend configuring AWS ParallelCluster to move those folders into EFS and mount them manually from there. AWS ParallelCluster will automatically do this for you if SharedStorageType : Efs is set in the cluster config YAML file.
Provision a separate EFS file system for Posit Workbench that will be used to provide /opt/rstudio and contain the Workbench configuration files (see above section on the systemctl override). It can be provisioned separately and then mounted by AWS ParallelCluster in the SharedStorage section of the YAML config file or directly provisioned by AWS ParallelCluster during the cluster deployment. It will be automatically mounted on all nodes of the cluster.
FSx for Lustre
The FSx for Lustre volume hosts user home directories and must be mounted to all Workbench and session nodes (login and compute, head node not needed). In order to enable separate management of user home directories and the AWS ParallelCluster stack, the use of an external file system is recommended. To do this, create or re-use an existing Lustre volume that will store home directories and set it as an external file system in the SharedStorage section of the YAML file. You need to mount this volume at /home.
Configure the same FSx file system to host the shared data of Workbench by setting server-shared-storage to /home/rstudio/shared-storage in rserver.conf. This is especially important for Workbench (and R) features that need to use POSIX ACLs.