Workbench-managed Databricks Credentials
Posit Workbench has a native integration for Databricks that includes support for managed Databricks OAuth credentials and a dedicated pane in the RStudio Pro IDE.
Workbench-managed credentials allow you to sign into a Databricks workspace from the home page and be immediately granted access to data and compute resources using your existing Databricks identity. Managed credentials avoid the burden (and risk) of managing Databricks personal access tokens (PATs) yourself, work with the Databricks CLI, most official packages and SDKs, and database drivers for Python and R. Anything that implements the Databricks client unified authentication standard will pick up the ambient credentials supplied by Workbench.
Workbench-managed Databricks credentials are refreshed automatically while your session is active.
Starting a Session with Workbench-managed Databricks credentials
If your administrator has configured and enabled the Databricks integration, a new drop-down displays in the New Session dialog. This allows you to select which Databricks workspace to connect to.
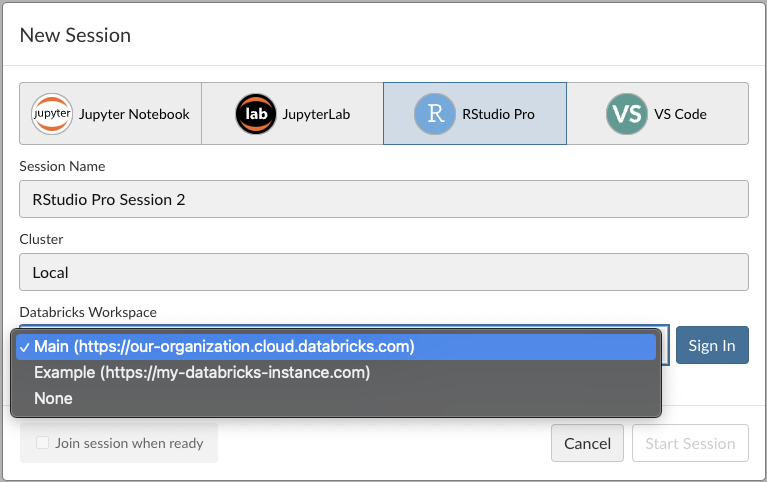
Select an option and then begin the authentication flow by clicking Sign In, if not already authenticated. If this completes successfully, the button updates to show that you’re now signed in.
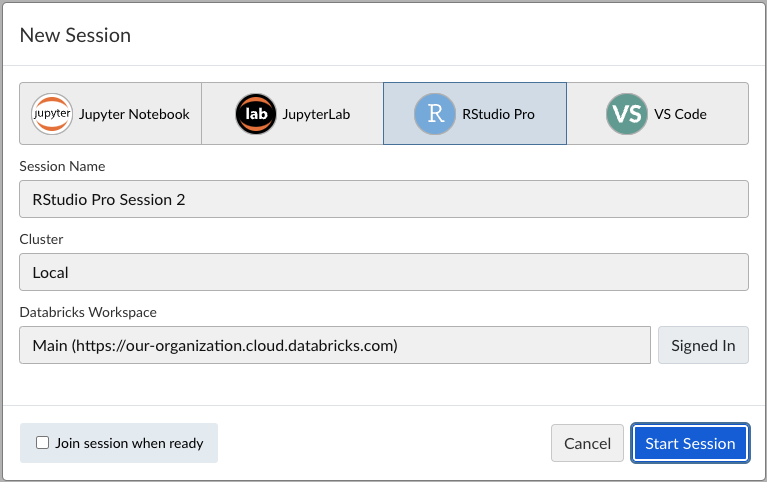
You can only start a session if you have signed in to that Databricks workspace. Selecting None will always allow you to begin a new session without any managed credentials.
If an error occurs in the authentication flow or too much time elapses between initiating the process and completing it, an error is displayed below the drop-down, and the Sign In button is replaced with the option to Retry the process.

If your Workbench administrator has enabled managed Databricks credentials, providing your PATs or host environment variables in a .env, .databrickscfg, .Renviron or other files may interfere with Workbench-managed credentials and lead to inconsistent behavior. If you want to opt out of managed credentials and instead use your own configuration, from the drop-down menu select None when starting sessions.
Databricks CLI
The Databricks CLI wraps the Databricks REST API and provides access to Databricks account and workspace resources and data. For more information, reference the Databricks REST API reference or the Databricks CLI documentation. Providing Databricks credentials is unnecessary when using the CLI with managed Databricks credentials inside Posit Workbench.
# List cluster metadata
databricks clusters get 1234-567890-a12bcde3Databricks with R
Workbench-managed Databricks credentials have been validated to work with sparklyr, odbc using the Posit Pro Driver for Databricks, and the Databricks R SDK. For more information about using the Databricks pane to manage clusters or sparklyr connections easily, or about the Connections pane in RStudio Pro, reference RStudio Pro: Databricks.
sparklyr version 1.8.4 or higher works with Workbench-managed credentials and modern Databricks Runtimes that make use of Databricks Connect (ML 13+). This is accomplished via reticulate and an additional pysparklyr package that powers sparklyr. For more information and installation instructions see the sparklyr package documentation.
library(sparklyr)
sc <- spark_connect(
cluster_id = "[Cluster ID]",
method = "databricks_connect",
dbr_version = "14.0"
)odbc version 1.4.0 or higher provides odbc::databricks() which will automatically handle many common authentication scenarios. Pair odbc with DBI if you want to write your own SQL:
library(DBI)
con <- dbConnect(
odbc::databricks(),
httpPath = "value found under Advanced Options > JDBC/ODBC in the Databricks UI"
)
dbGetQuery(con, "
SELECT passenger_count, AVG(fare_amount) AS avg_fare
FROM nyctaxi
WHERE trip_distance > 0.5
GROUP BY passenger_count
")Or use dbplyr to generate SQL from your dplyr code:
library(dbplyr)
library(dplyr, warn.conflicts = FALSE)
nyctaxi <- tbl(con, in_catalog("samples", "nyctaxi", "trips"))
nyctaxi |>
filter(trip_distance > 0.5) |>
summarise(
avg_fare = mean(fare_amount),
.by = passenger_count
)The R Databricks SDK can be used for general Databricks operations:
library(databricks)
client <- DatabricksClient()
# List clusters
clustersList(client)[, "cluster_name"]Databricks with Python
Workbench-managed credentials are expected to work with Python tools that adhere to the Databricks client unified authentication standard. The following have been tested in Posit Workbench: pyodbc, Databricks VS Code extension, Databricks CLI, Databricks SDK for Python, and pyspark via Databricks Connect.
pyodbc has been validated with Posit’s Databricks Pro Driver in VS Code.
import configparser
import os
import pyodbc
import re
# open the DATABRICKS_CONFIG_FILE to get oauth token information
config = configparser.ConfigParser()
config.read(os.environ["DATABRICKS_CONFIG_FILE"])
# Replace <table-name> with the name of the database table to query.
table_name = "samples.nyctaxi.trips"
databricks_host = os.environ["DATABRICKS_HOST"]
databricks_workspace_id = "138962681435081"
databricks_cluster_id = "1108-152427-dq9mgl"
databricks_http_path = (
f"sql/protocolv1/o/{databricks_workspace_id}/{databricks_cluster_id}"
)
databricks_oauth_token = config["workbench"]["token"]
# Setup the connection string for the Databricks instance
connection_string = f"""
Driver = /opt/simba/spark/lib/64/libsparkodbc_sb64.so;
Host = {databricks_host};
HTTPPath = {databricks_http_path};
Port = 443;
Protocol = https;
UID = token;
SparkServerType = 3;
Schema = default;
ThriftTransport = 2;
SSL = 1;
AuthMech = 11;
Auth_Flow = 0;
Auth_AccessToken = {databricks_oauth_token};
"""
# remove spaces from connection string
connection_string = re.sub(r"\s+", "", connection_string)
# connect to the Databricks instance
conn = pyodbc.connect(connection_string, autocommit=True)PySpark is a Python API for working with Apache Spark and can be used with Databricks managed Spark environments. It can be used for SQL or dataframe operations as well as machine learning algorithms via MLlib.
from pyspark.sql import SparkSession
spark: SparkSession = spark
print("Hello from Databricks")
spark.sql("select * from samples.nyctaxi.trips").show(3)The .databrickscfg file that Posit Workbench manages for you has a profile called “workbench” containing the short-lived tokens and other metadata for connecting.
from databricks.connect import DatabricksSession
from databricks.sdk.core import Config
# Optional to specify the profile
config = Config(profile="workbench", cluster_id="1234-abcdef-5678hijk")
spark = DatabricksSession.builder.sdkConfig(config).getOrCreate()
# PySpark code executed on Databricks Cluster
df = spark.read.table("samples.nyctaxi.trips")
df = df.filter(df.trip_distance > 0.5)
df_pd = df.limit(3).toPandas()
# Python code executed on local machine
print(df_pd)Python SDK
This brief example prints the available clusters based on your user profile, using the Databricks profile (profile="workbench") that Workbench-managed credentials provides.
from databricks.sdk import WorkspaceClient
# Connect to the Databricks instance
# Optional to specify the profile
w = WorkspaceClient(profile="workbench")
# Retrieve the list of clusters
clusters = w.clusters.list()
# Print the names of the clusters
for c in clusters:
print(c.cluster_name)